바로 다음 이어서 가겠습니다!
#9-4 연령대에 따른 월급의 차이 - "어떤 연령대의 월급이 가장 많을까?"
9-3에서 한 것과 유사하지만 나이가 아닌 연령대로 보겠습니다!
연도 변수를 활용하여 나이 변수를 파생한 것처럼 연도 변수를 활용하여 연령대 변수를 만들어 활용하면 정답~
임의로 다음과 같이 기준을 설정해보겠습니다.
| 범주 | 기준 |
| 초년 | 30세 미만 |
| 중년 | 30~59세 |
| 노년 | 60세 이상 |
step1) 변수 검토 및 전처리
ifelse 함수를 두 번 활용하여 세 개의 범주를 나눠주면 됩니다! 여기선 mutate 함수도 같이 해줘야합니다!
welfare <- welfare %>%
+ mutate(ageg = ifelse(age < 30, "young",
+ ifelse(age < 60, "middle", "old")))table(welfare$ageg)
middle old young
6049 6281 4334 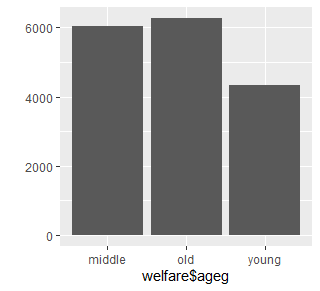
변수 검토 시 table, qplot 이제는 자동으로 따라와야겠죠?!
step2) 연령대에 따른 월급 차이 분석하기
연령대에 따른 월급 평균표를 만들어보겠습니다!
똑같이 월급 변수에 결측치가 없는 것으로 filter, 연령대 별로 group_by, summarise로 ageg_income!
ageg_income <- welfare %>%
+ filter(!is.na(income)) %>%
+ group_by(ageg) %>%
+ summarise(mean_income = mean(income))ageg_income
# A tibble: 3 × 2
ageg mean_income
<chr> <dbl>
1 middle 282.
2 old 125.
3 young 164.연령대에 따른 월급 평균표 확인 완료!
다음은 그래프 만들기 시작!
데이터는 ageg_income을, x축은 ageg, y축은 mean_income!
ggplot(data = ageg_income, aes(x = ageg, y = mean_income)) + geom_col()
이렇게 우리가 아는 선에서 그래프를 만들었습니다! 하지만 여기서 불편한점,, 연령대 순서대로 안나온 거 너무너무 불편합니다... 이것은 ggplot()이 박대를 변수의 알파벳 순으로 정렬하도록 기본값이 설정되어있기 때문입니다! 이를 변경해주기 위해서는 scale_x_discrete(limits = c())에 범주 순서를 지정하면 됩니다!
ggplot(data = ageg_income, aes(x = ageg, y = mean_income)) + geom_col() +
+ scale_x_discrete(limits = c("young", "middle", "old"))
아주 편합니다! 이렇게 연령대에 따른 월급 차이 분석 완!
#9-5 연령대 및 성별 월급 차이 - "성별 월급 차이는 연령대별로 다를까?"
이번 분석은 이전에 진행했던 연령대별, 성별별 월급의 차이를 한 그래프에 담아내는 것이 목표입니다!
세 변수들에 대한 검토 및 전처리는 완료되었으니 바로 시작해보겠습니다!
이때는, group_by를 연령대, 성별 두 변수 모두 설정하여 분석해야합니다.
sex_income <- welfare %>%
+ filter(!is.na(income)) %>%
+ group_by(ageg, sex) %>%
+ summarise(mean_income = mean(income))sex_income
# A tibble: 6 × 3
# Groups: ageg [3]
ageg sex mean_income
<chr> <chr> <dbl>
1 middle female 188.
2 middle male 353.
3 old female 81.5
4 old male 174.
5 young female 160.
6 young male 171. 이렇게 ageg, sex 순으로 지정했기에 ageg를 먼저 나누고, 그 내에서 성별로 나뉘어진 평균표를 볼 수 있습니다.
다음으로 그래프를 만들어보겠습니다.
두 가지 변수를 한 그래프에 담기 위해서는 fill이라는 코드가 aes 안에 들어가야됩니다! 코드를 살펴보겠습니다.
연령대 순도 이전과 같이 한 번에 진행할게요!
ggplot(data = sex_income, aes(x = ageg, y = mean_income, fill = sex)) + geom_col() +
+ scale_x_discrete(limits = c("young", "middle", "old"))이렇게 코드를 실행해주면, 다음과 같은 결과가 나오게됩니다.

이렇게 실행하였을 때 단점은 한 눈에 연령대와 성별에 따른 월급의 분포를 알아볼 수 없다는 것입니다. 두 변수가 평행하게 분리되어있어야 확인이 쉬울텐데 말이죠! 그러한 결과를 얻기 위해서는 geom_col() 내부에 position 파라미터를 "dodge"로 설정해주면 됩니다.
ggplot(data = sex_income, aes(x = ageg, y = mean_income, fill = sex)) +
+ geom_col(position = "dodge") +
+ scale_x_discrete(limits = c("young", "middle", "old"))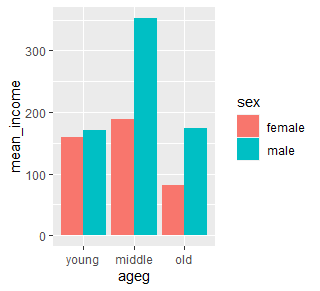
한 눈에 알아보기 쉽죠! 성별 월급 차이의 양상이 연령대별로 다르다는 것을 알수 있고, 초년에 차이가 크지 않고, 중년에 차이가 매우 크며, 노년에 남성의 월급이 더 높다는 것을 알 수 있습니다!
#9-6 직업별 월급 차이 - "어떤 직업이 월급을 가장 많이 받을까?"
이번에는 직업별 월급 차이! 지금까지 계속 해왔기 때문에 직업 변수에 대한 검토와 전처리만 하면 된다는 것을 알게 되겠죠?
step1) 변수 검토 및 전처리
- 변수 검토하기
library(readxl)
> class(welfare$code_job)
[1] "numeric"
> table(welfare$code_job)
111 120 131 132 133 134 135 139 141 149 151 152 153 159 211 212 213 221 222
2 16 10 11 9 3 7 10 35 20 26 18 15 16 8 4 3 17 31
223 224 231 232 233 234 235 236 237 239 241 242 243 244 245 246 247 248 251
12 4 41 5 3 6 48 14 2 29 12 4 63 4 33 59 77 38 14
252 253 254 259 261 271 272 273 274 281 283 284 285 286 289 311 312 313 314
111 24 67 109 4 15 11 4 36 17 8 10 26 16 5 140 260 220 84
320 330 391 392 399 411 412 421 422 423 429 431 432 441 442 510 521 522 530 항상 변수 검토에 앞서 class를 통해 변수가 어떤 형태를 띠고 있는지 확인하고, table을 통해 어떤 범주가 존재하는지 확인하는 과정을 거쳐야합니다! 직업 변수는 굉장히 많아서 중간 결과를 잘랐습니다!
code_job은 직업 코드를 의미하며, 우리가 사용하는 복지패널데이터에는 직업에 대한 숫자 코드로 입력되어 있어 우리가 이를 직업 명칭 변수를 만들어줘야됩니다!
-전처리
숫자 코드로 된 직업들을 우리가 사용할 수 있는 하나의 문자로 만들어줘야되겠죠!
이 프로젝트에서는 left_join을 활용하여 welfare$code_job과 직업분류코드 목록 데이터 프레임을 합쳐 진행합니다!
그러기 위해서 직업분류코드 목록 데이터 프레임을 불러오기 위해 readxl 패키지를 로드할 예정입니다.
list_job <- read_excel("Koweps_Codebook.xlsx", col_names = T, sheet = 2)
> head(list_job)
# A tibble: 6 × 2
code_job job
<dbl> <chr>
1 111 의회의원 고위공무원 및 공공단체임원
2 112 기업고위임원
3 120 행정 및 경영지원 관리자
4 131 연구 교육 및 법률 관련 관리자
5 132 보험 및 금융 관리자
6 133 보건 및 사회복지 관련 관리자 다음과 같이 말이죠! readxl 패키지의 read_excel 함수는 괄호 안에 불러올 엑셀 파일명, col_names = T, sheet = n 을 통해 불러올 수 있습니다! col_names는 첫 행을 변수명으로 가져오도록 하고 sheet 파라미터에 우리가 취하고자 하는 숫자를 지정해주면 됩니다!
이렇게 진행하게되면, 우리가 갖고 있는 welfare에 code_job을 이용하여 job을 추가할 수 있을 것 같습니다!
left_join은 베이스가 되는 데이터 프레임, 추가하고자 하는 데이터 프레임, by = 공통으로 존재하는 변수를 입력하면 되는거 기억하시죠!
welfare <- left_join(welfare, list_job, by = "code_job")위의 코드로 실행하면,
welfare %>%
+ filter(!is.na(code_job)) %>%
+ select(code_job,job) %>%
+ head(5)
code_job job
1 942 경비원 및 검표원
2 762 전기공
3 530 방문 노점 및 통신 판매 관련 종사자
4 999 기타 서비스관련 단순 종사원
5 312 경영관련 사무원이렇게 전처리 완료!!
step2) 변수 간 관계 분석
다음은 직업별 월급 평균표를 만들어야하죠!
직업과 월급에 결측치를 제외하고 다뤄야 한다는 점 잊으면 안됩니다!
job_income <- welfare %>%
+ filter(!is.na(job) & !is.na(income)) %>%
+ group_by(job) %>%
+ summarise(mean_income = mean(income))
> head(job_income)
# A tibble: 6 × 2
job mean_income
<chr> <dbl>
1 가사 및 육아 도우미 80.2
2 간호사 241.
3 건설 및 광업 단순 종사원 190.
4 건설 및 채굴 기계운전원 358.
5 건설 전기 및 생산 관련 관리자 536.
6 건설관련 기능 종사자 247. 직업별 월급을 보는 것이기 때문에, 월급에 대해 내림차순, 오름차순으로 한 번씩 정렬해보겠습니다.
arrange 함수를 파이프라인으로 추가해서 보면 되겠죠?
top10 <- job_income %>%
+ arrange(desc(mean_income)) %>%
+ head(10)
> top10
# A tibble: 10 × 2
job mean_income
<chr> <dbl>
1 금속 재료 공학 기술자 및 시험원 845.
2 의료진료 전문가 844.
3 의회의원 고위공무원 및 공공단체임원 750
4 보험 및 금융 관리자 726.
5 제관원 및 판금원 572.
6 행정 및 경영지원 관리자 564.
7 문화 예술 디자인 및 영상 관련 관리자 557.
8 연구 교육 및 법률 관련 관리자 550.
9 건설 전기 및 생산 관련 관리자 536.
10 석유 및 화학물 가공장치 조작원 532.상위 10개 직업
bottom10 <- job_income %>%
+ arrange(mean_income) %>%
+ head(10)
> bottom10
# A tibble: 10 × 2
job mean_income
<chr> <dbl>
1 가사 및 육아 도우미 80.2
2 임업관련 종사자 83.3
3 기타 서비스관련 단순 종사원 88.2
4 청소원 및 환경 미화원 88.8
5 약사 및 한약사 89
6 작물재배 종사자 92
7 농립어업관련 단순 종사원 102.
8 의료 복지 관련 서비스 종사자 104.
9 음식관련 단순 종사원 108.
10 판매관련 단순 종사원 117. 하위 10개 직업
이렇게 평균표를 보고 나서 그래프를 만들어야합니다!
ggplot(data = top10, aes(x = reorder(job, mean_income), y = mean_income)) +
+ geom_col()우리가 알고 있듯이, top10이라는 데이터를 mean_income을 기준으로 x축 변수를 정렬하고, y축 변수를 막대 그래프로 설정하면 됩니다.

하지만, 이렇게 설정하게 되면 문제점이 x축의 변수들이 긴 글자로 되어있기 때문에 가독성이 매우매우 떨어진다는 것입니다. 따라서 coord_flip() 함수를 설정하여 오른쪽으로 90도 회전시켜보겠습니다.
ggplot(data = top10, aes(x = reorder(job, mean_income), y = mean_income)) +
+ geom_col() + coord_flip()
이렇게 가독성을 챙길 수 있습니다!
그래프를 통해 금속 재료 공학 기술자 및 시험원이 가장 높은 월급을 가진다는 것을 알 수 있습니다.
하위 10개 직업에 대한 그래프도 살펴보겠습니다.
ggplot(data = bottom10, aes(x = reorder(job, -mean_income), y = mean_income)) + geom_col() + coord_flip()
이렇게 하위 10개 직업에 대한 월급도 알아볼 수 있으며, 상위 10개 직업과 비교 분석을 위해 ylim함수를 상위 10개 직업의 기준과 맞춰 그래프를 만들어 볼 수 있습니다!!
이렇게 프로젝트 두 번째 포스트도 마무리하겠습니다!
감사합니다!!
'R' 카테고리의 다른 글
| 데이터 분석 시작기-18 (텍스트 마이닝) (0) | 2023.02.27 |
|---|---|
| 데이터 분석 시작기-17 (데이터 분석 프로젝트_3) (0) | 2023.02.07 |
| 데이터 분석 시작기-15 (데이터 분석 프로젝트_1) (0) | 2023.02.05 |
| 데이터 분석 시작기-14 (그래프 만들기) (0) | 2023.02.01 |
| 데이터 분석 시작기-13 (데이터 정제- 이상치 제거) (0) | 2023.01.31 |