#2 변수명 바꾸기
이전 시작기와 이어서 진행해 보겠습니다! 길어서 잘라봤습니다! 하지만 시작기-6편 시작합니다!
이전에는 데이터의 전반적인 특징을 파악해 보았습니다. 하지만, 분석하기 전에 변수명을 수정할 필요가 생길 수 있습니다. 이는 데이터를 수월하게 다룰 수 있다는 장점이 있죠!
실제로 이 책에서 다루는 데이터 중 '한국복지패널데이터'는 응답자의 성별이 h0901_4 혹은 소득이 h09_din 등 다루기 어려운 변수명을 갖고 있지만, 우리는 이를 성별은 sex로, 소득은 income으로 변경하여 쉽게 다룰 수 있도록 해야 합니다!
이번 챕터에서는 dplyr이라는 패키지를 사용해 보겠습니다! 그중 rename()이라는 함수를 사용할 것이며, 자세한 내용은 다음 챕터에서 다룰 테니 넘어가 보겠습니다,,ㅎ 전에, dplyr 패키지 다운하는 것까지만!

이렇게 입력해서 패키지를 다운, 패키지를 로드하면 사용할 준비 완료! *패키지 다운은 초기 1회만, 로드는 studio 켤 때마다!
진짜 시작!
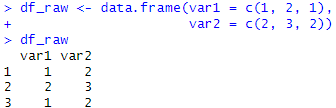
실습에 활용할 데이터 프레임을 만들어 보았습니다! df_raw라는 데이터 프레임을 만들었으며, 각각의 변수명은 var1, var2 입니다.
다음은 현대 사회에서 가장 중요한 데이터 날아감 방지.... 복사본을 만들어 보겠습니다! 군대에서도 항상 파일의 복사본은 만들었던 것 같습니다.. 여기서도 복사본 꼭!!! 만들어 놓고 활용하기로!
복사본은 새로운 데이터 프레임명을 정하고 단순히 기존의 데이터 프레임을 입혀주는 방식으로 진행하면 됩니다!
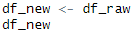
모든 준비가 완료되었습니다! 패키지를 설치 및 로드하고, 데이터 프레임을 만들고, 복사본까지!
변수명으르 바꿀 때, rename()을 활용한다고 했습니다. 괄호 안에 데이터 프레임명, 새 변수명 = 기존 변수명을 입력하면 수정이 완료됩니다! 순서가 바뀌면 실행이 안 되니 확인 꼭!
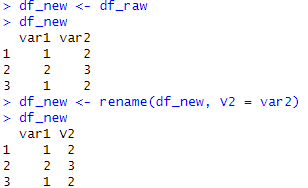
한눈에 보기 쉽게 사진을 따왔습니다! 기존의 df_new의 var2가 v2로 바뀐 모습을 확인할 수 있습니다.
#3 파생변수 만들기
우리는 데이터 프레임에 있는 데이터만을 활용하여 분석을 진행하는 경우도 있지만, 이들을 조합한 새로운 변수를 만들어서 분석을 할 수도 있습니다!
방법을 알아보겠습니다!

새로운 데이터 프레임을 우선 만들어야 모든 과정을 진행할 수 있습니다! 이번 데이터 프레임명은 "df"로 지정하였습니다.
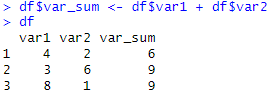
var1과 var2를 더한 var_sum이라는 파생 변수를 만들었습니다! 이전에도 설명했듯이 $는 데이터 프레임 내부에 하나의 열을 지정하는 하나의 기호입니다! 위의 방식을 통해 새로운 파생변수를 삽입하였습니다!
더한 값뿐만 아니라 두 변수의 평균값을 파생변수로서 만들 수 있습니다!
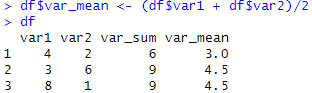
이렇게 간단한 파생변수 만드는 과정을 알아보았습니다!
ggplot2 내 mpg 데이터를 활용하여 여러 가지 파생변수를 만들어 보겠습니다!
1) mpg 데이터 내 통합 연비 변수 만들기
mpg 데이터 내 도시 연비(cty), 고속도로 연비(hwy) 두 변수의 통합 연비 변수를 만들어 보겠습니다! 통합 연비 변수는 두 연비를 더하고 2를 나눈 값이겠죠?

total이라는 새로운 변수를 이전과 같은 방식으로 만들고, head 함수를 이용하여 2개의 행만 나타냈습니다! 참 쉽죠? 사실 저는 어려워요ㅠㅠ
2) 합격 판정 변수 만들기
이번 변수는 새로운 방식으로 만들어야 합니다! 조건문을 활용해서 만드는 과정을 설명하겠습니다.
기준값을 정한 후, ifelse라는 함수를 활용하여 데이터 프레임 내 특정 변수의 값이 기준값보다 크거나 작다는 조건을 활용해 해당 값을 부여하는 것입니다.
2-1) 기준값 정하기
기준값을 어떻게 정하느냐는 개개인의 필요에 따라 달라지겠지만, 데이터 파악하는 과정에서 활용한 summary() 함수를 활용해 어느 분포를 갖는지 확인하고, 새로운 함수 hist() 함수를 활용하여 히스토그램을 생성하여 개개인의 기준을 설정하면 됩니다.
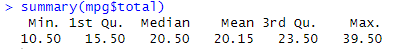
통합 연비 변수의 요약 통계량을 확인하여 중앙값 혹은 평균값을 확인합니다.
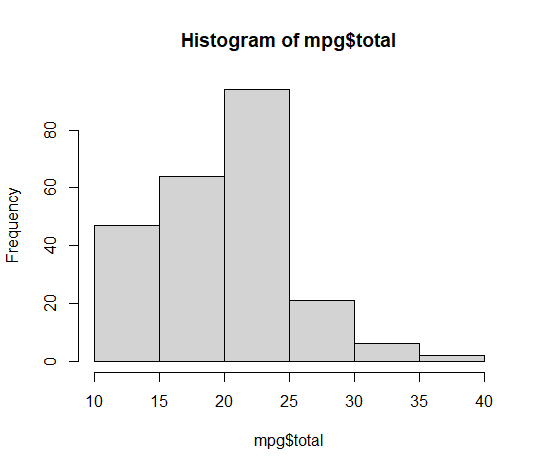
요약 통계량과 히스토그램을 통해 파악한 것은 20을 기준으로 많은 데이터들이 존재하며, 이를 기준값으로 정하기 좋아 보입니다.
2-2) 합격 판정 변수 만들기
합격 판정 변수는 위에서 설명한 대로 진행해 보겠습니다!

합격 판정 변수를 ifelse를 활용하여 만들었습니다! 이상 혹은 이하는 >=, <=를 활용하여 나타내면 됩니다!
우리가 확인하고자 하는 범위가 하나라고 할 수는 없겠죠? 이때는 중첩 조건문을 활용하면 됩니다!
ifelse(데이터 조건, "A", ifelse(데이터 조건, "B", :"C)) 이러한 방식으로 ifelse 내부에 한 번 더 ifelse를 넣어주면 됩니다! 한 개가 아니라 두 개가 될 수도 있고, 세 개가 될 수도 있습니다! 분석을 진행하는 사람이 원하는 대로!!!!
2-3) 빈도표로 합격 판정 자동차 수 살펴보기
저는 빈도표를 활용하여 살펴보는 것이 제일 낯설고 손이 안 가더라고요,, 아직 안 친해진 탓이라고 생각합니다,,
빈도표를 만드는 함수는 table() 함수로, 괄호 안에 확인하고 싶은 데이터를 넣어주면 됩니다!
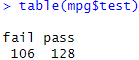
이를 막대그래프로도 나타낼 수 있다는 사실!
ggplot2 패키지에 내장된 여러 함수 중 qplot을 활용하면 성공!
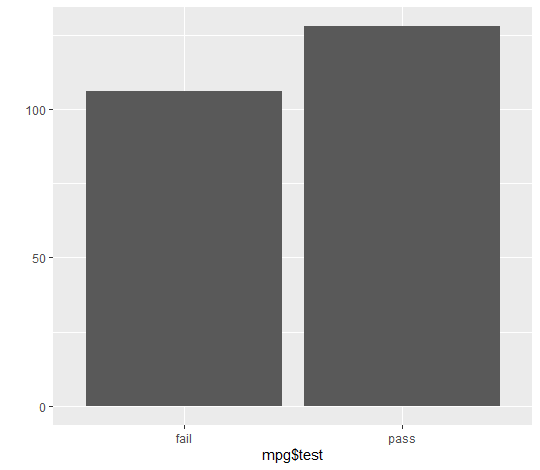
이렇게 여러 가지 파생 변수를 만드는 과정을 살펴보았습니다!
어렵지만 계속해서 다뤄보겠습니다!
감사합니다!
'R' 카테고리의 다른 글
| 데이터 분석 시작기-8 (데이터 전처리 - 변수 추출 및 정렬;select, arrange) (0) | 2023.01.24 |
|---|---|
| 데이터 분석 시작기-7 (데이터 전처리 - 행 추출;filter) (0) | 2023.01.24 |
| 데이터 분석 시작기-5 (데이터 파악 및 수정) (0) | 2023.01.18 |
| 데이터 분석 시작기-4 (데이터 프레임 이해하기) (0) | 2023.01.17 |
| 데이터 분석 시작기-3 (패키지 이해하기) (0) | 2023.01.05 |