데이터 분석 시작기-19 (단계 구분도 만들기)
안녕하세용!
거의 한 달만의 포스팅입니다,, 개인적으로 기록하며 포트폴리오 느낌으로 꾸준히 만들어보려 했으나,, 하와이에 와 있습니다!
어학연수를 3월 초에 와서 이곳에서 현생을 살다 보니 휴양지 느낌을 거의 3주를 만끽하고 제 본업인 학생임을 잊고 살았네요ㅠㅠ 그래도 열심히 해보겠습니다!
각설하고, 이번에는 단계 구분도를 만들어 보려 합니다.
단계 구분도란, 지역별 통계치를 색깔의 차이로 표현한 지도입니다!
이를 통해 인구나 소득 같은 특성이 지역별로 얼마나 다른지 쉽게 이해할 수 있습니다!
두 가지 데이터를 통해 단계 구분도를 만들어 볼 것이며, 첫 번째 데이터는 '미국 주별 강력 범죄율', 두 번째 데이터는 '대한민국 시도별 인구, 결핵 환자 수'입니다!
바로 시작해 보시죠!
단계 구분도를 만들기 전, 패키지를 설치하고 로드해야 합니다!
install.packages("mapporj")install.packages("ggiraphExtra")library(ggiraphExtra)먼저, ggiraphExtra 패키지를 이용하는데 필요한 mapproj 패키지를 설치하고 ggiraphExtra 패키지를 설치 후 로드 완!
<미국 주별 범죄 데이터 준비하기>
이 데이터는 R에 내장되어 있으며, 바로 로드해도 문제없습니다!
정보를 바로 확인해 보겠습니다~
str(USArrests)
'data.frame': 50 obs. of 4 variables:
$ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
$ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
$ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
$ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...str은 각각의 변수들이 어떻게 구성되어 있는지 확인하는 것! 잊지 않으셨죠?
head(USArrests)
Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7head를 통해 각각의 데이터들이 어떠한 변수들을 갖고 있는지 6행까지 확인!
확인해 본 결과 지역명 변수가 따로 없고, 행 이름이 지역명으로 되어 있기 때문에, 행 이름을 state 변수로 바꿔 새로운 데이터 프레임을 만들어 보겠습니다!
library(tibble)tibble 패키지의 rownames_to_column()을 이용해야하기 때문에 로드하고 갑니다!
tibble 패키지는 dplyr을 설치하면 자동으로 함께 설치되니 걱정 No!
crime <- rownames_to_column(USArrests, var = "state")새로운 데이터 프레임을 crime으로 만들면서, 기존 USArrests 데이터의 행 이름을 열 이름(state)으로 설정하는 과정입니다!
이후 데이터의 지역명 변수를 소문자로 설정해 보는 과정도 해보겠습니다!
crime$state <- tolower(crime$state)tolower 함수를 활용하여 crime$state 설정하면 됩니다!
str(crime)
'data.frame': 50 obs. of 5 variables:
$ state : chr "alabama" "alaska" "arizona" "arkansas" ...
$ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
$ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
$ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
$ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...str로 확인한 결과 각 열들의 데이터들을 확인할 수 있고, state도 잘 들어가 있는 것을 확인!
<미국 주 지도 데이터 준비>
지도 데이터를 활용하는 단계 구분도에서 가장 중요한 단계라고 생각됩니다!
지역별 위도, 경도 정보가 있는 지도 데이터를 로드하기 위해, 미국주별 위경도 데이터가 들어있는 maps 패키지를 설치하고, ggplot2 패키지의 map_data()를 이용해 데이터 프레임 형태로 불러오는 과정을 보이겠습니다!
install.packages("maps")library(ggplot2)states_map <- map_data("state")str(states_map)
'data.frame': 15537 obs. of 6 variables:
$ long : num -87.5 -87.5 -87.5 -87.5 -87.6 ...
$ lat : num 30.4 30.4 30.4 30.3 30.3 ...
$ group : num 1 1 1 1 1 1 1 1 1 1 ...
$ order : int 1 2 3 4 5 6 7 8 9 10 ...
$ region : chr "alabama" "alabama" "alabama" "alabama" ...
$ subregion: chr NA NA NA NA ...위의 전체적인 과정입니다. states_map에 위경도 데이터들이 있음을 확인할 수 있습니다.
<단계 구분도 만들기>
지금까지의 과정이 1) 지도에 표현할 범죄 데이터와 2) 배경이 될 지도 데이터를 준비하는 과정이었습니다.
데이터들을 활용하여 ggiraphExtra 패키지의 ggChoropleth()를 이용해 단계 구분도를 만들어 보겠습니다.
ggChoropleth(data = crime, #지도에 표현할 데이터
+ aes(fill = Murder, #색깔로 표현할 변수
+ map_id = state), #지역 기준 변수
+ map = states_map) #지도 데이터ggChoropheth()에는 여러 추가 과정이 필요합니다. data를 설정하고, fill을 통해 색깔로 표현할 변수를 확인, map_id가 지역 기준 변수를, 마지막으로 map을 지도 데이터로 설정해야 합니다.
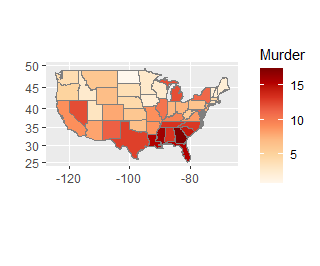
이렇게 최종 결과를 얻을 수 있습니다.
이에 추가적으로 <인터랙티브 단계 구분도>라는 것을 만들어 보겠습니다.
인터랙티브란, 마우스 움직임에 반응하는 것을 말합니다. 마우스를 올렸을 때 해당 지역들이 반응(?)하는 것!
마지막 지도 데이터 이후에 interactive 파라미터를 True로 설정해 주면 됩니다!
ggChoropleth(data = crime, #지도에 표현할 데이터
+ aes(fill = Murder, #색깔로 표현할 변수
+ map_id = state), #지역 기준 변수
+ map = states_map, #지도 데이터
+ interactive = T) #인터랙티브사진으로는 담기지 않습니다ㅠㅠ 다들 한 번 시도해 보는 것도 좋을 것 같아요!
이번에는 다음 데이터를 활용한!!!
대한민국 시도별 인구, 결핵 환자 수 단계 구분도 만들기!!
이번 데이터는 kormaps2014 패키지를 활용할 것입니다!
<패키지 준비하기>
먼저, kormaps2014 패키지를이용하는 데 필요한 stringi 패키지를 설치하고, devtools 패키지를 설치 후 install_github를 이용해 패키지 개발자가 깃허브에 공유한 kormaps2014를 설치 및 로드하는 과정입니다.
install.packages("stringi")install.packages("devtools")devtools::install_github("cardiomoon/kormaps2014")library(kormaps2014)
<대한민구구 시도별 인구 데이터 준비>
kormaps2014에는 시도별 / 시군구별 / 읍면동별 데이터 정보가 존재합니다. 그 중 시도별 데이터인 korpop1을 사용하여 진행하겠습니다!
library(dplyr)
> korpop1 <- rename(korpop1, pop = 총인구_명, name = 행정구역별_읍면동)
> korpop1$name <- iconv(korpop1$name, "UTF-8", "CP949")R에서 가장 중요한 한글이 오류를 만들어낼 수도 있다는 것을 다들 알고 있을 것입니다!
따라서 이들을 영어로 만들어 주기 위해 rename 함수를 쓴 것이며, 항상 dplyr 함수를 로딩하기!
"UTF-8"은 인코딩 변경을 하는 것입니다! "CP949"로!
<대한민국 시도 지도 데이터 준비하기>
kormaps2014에는 지도 데이터도 있습니다!
그 중 시도별 데이터를 포함하는 kormap1을 사용!
<단계 구분도 만들기>
이전 데이터인 '미국 주별 범죄율'과 동일하게 코드를 짜면 됩니다!
ggChoropleth(data = korpop1, # 지도에 표현할 데이터
+ aes(fill = pop, # 색깔로 표현할 변수
+ map_id = code, # 지역 기준 변수
+ tooltip = name), # 지도 위에 표시할 지역명
+ map = kormap1) # 지도 데이터
똑같은 kormaps2014를 활용하여 지역별 결핵 환자 수도 만들어 보겠습니다!
ggChoropleth(data = tbc,
+ aes(fill = NewPts,
+ map_id = code,
+ tooltip = name),
+ map = kormap1)
이렇게 단계 구분도를 만드는 연습을 해봤습니다!
확실히 코드를 달리하고 한글이 들어간 데이터를 활용하니 많은 어려움이 있었지만, 차근차근 하다보면 모두들 할 수 있을 것입니다!
R 마스터가 되기까지 모두 화이팅:)